
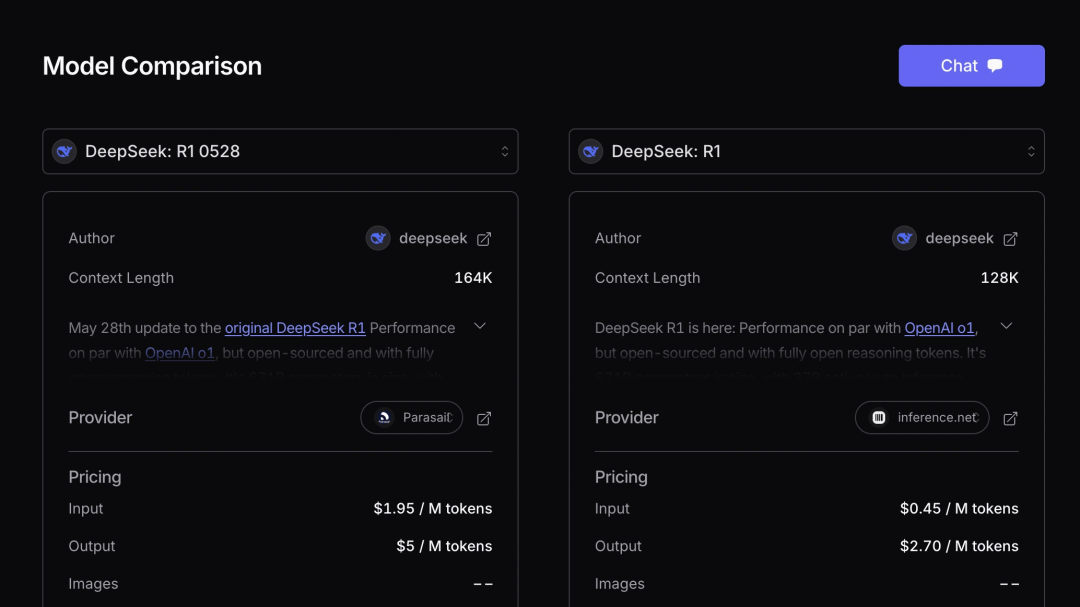
交易所,交易所排名,交易所排行,加密货币交易所排行榜,加密货币是什么,加密货币交易平台,加密货币平台,币安交易所,HTX火币交易所,欧意交易所,Bybit交易所,Coinbase交易所,Bitget交易所,Kraken交易所,交易所权威推荐,全球交易所排名,虚拟货币交易所排名,加密货币,加密货币是什么虽然不是DeepSeek R2,但据众多网友实际测评,新版DeepSeek R1在性能和体验上有明显提升,并非只是DeepSeek官方所说的“微小变化” ,而有Berkeley背景的代码测试平台Live CodeBench中显示,DeepSeek-R1-0528当前已达第四,不过这个榜单没有Claude 4。而根据X(Twitter)博主OpenRouterAI的比较,新版的确有变化,上下文长度(context length)更长,也更贵了。
此次R1升级版本的发布,似乎意在回应外界质疑,为逐渐冷却的市场情绪重新“加温”。此前,多家媒体曾报道称,DeepSeek计划在四月底至五月初发布新一代R2模型,甚至一度传出“提前上线日,梁文锋及其团队发布一篇14页论文,详述在DeepSeek-V3的研发过程中,如何借助2048块H800 GPU实现超大规模集群等效训练,人们又开始期待R2在架构上的继续升级,而此次的R1的发布,似乎显得比较有策略,既回应了用户期待,又给自己留足了升级架构的时间。
彼时金融行业大多数公司尚未了解AI大模型是何物,幻方量化再次于2019年前瞻性地大规模布局AI算力,自主研发“萤火一号”训练平台,投资近2亿元,配备1100块GPU。2021年,投资加码到10亿元的“萤火二号”投入使用,搭载约1万张英伟达A100显卡。凭借如此前期准备,恰逢2023年AI大模型迎来爆发之年,梁文锋宣布正式进军通用人工智能领域,创办杭州深度求索人工智能基础技术研究有限公司,即DeepSeek。
DeepSeek采用差异化的技术路线,开发了新型MLA(多头潜在注意力机制)和MoE架构,大幅降低显存占用和推理成本,仅为传统MHA架构的5%-13%,2024年12月26日,DeepSeek发布V3模型,使用2048颗H800 GPU,训练成本仅557.6万美元(对比GPT-4o的7800万美元),性能却超越多个开源模型,如Llama 3.1 405B,并可与GPT-4o、Claude 3.5 Sonnet等闭源模型竞争,被硅谷称为“来自东方的神秘力量”。
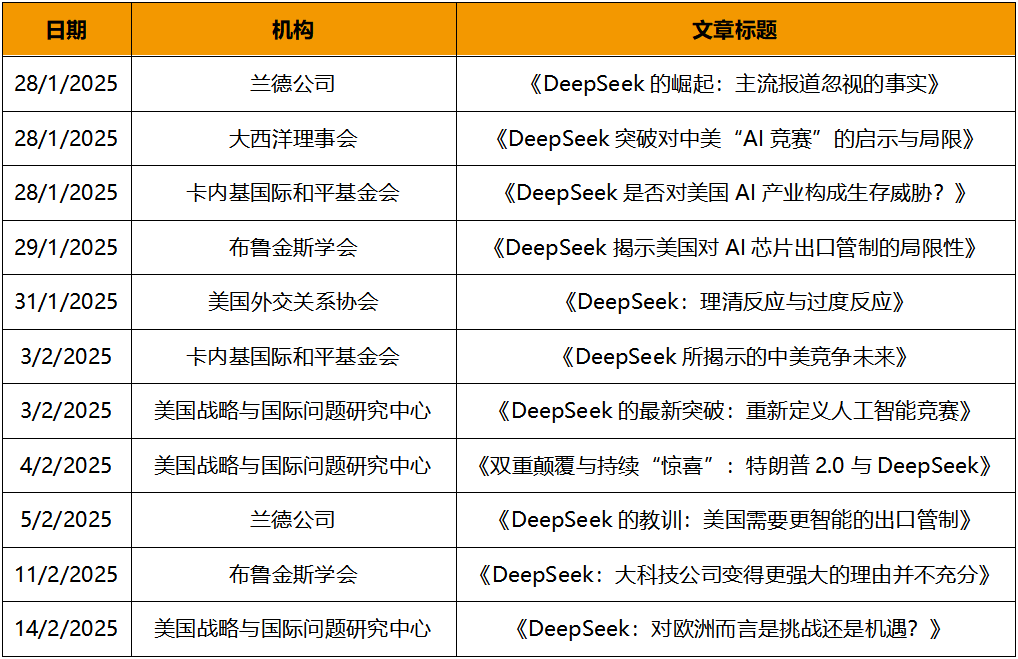
对于前者,DeepSeek主动公开其模型代码、技术论文及训练细节,例如其发布53页技术报告,详细披露R1的训练细节,对于后者,DeepSeek则通过学术界背书,如MIT媒体实验室的审计报告,证明其隐私保护强度高于美国企业平均水平,还通过法律团队向欧盟监管机构提交合规说明,解释数据跨境传输的加密措施,此外DeepSeek能借助开源优势,在Github、Huggingface等技术社区与开发者积极互动,以Github为例,其中DeepSeek V3的Star数量达到9.72万,DeepSeek R1的Star数量也能达到8.95万。
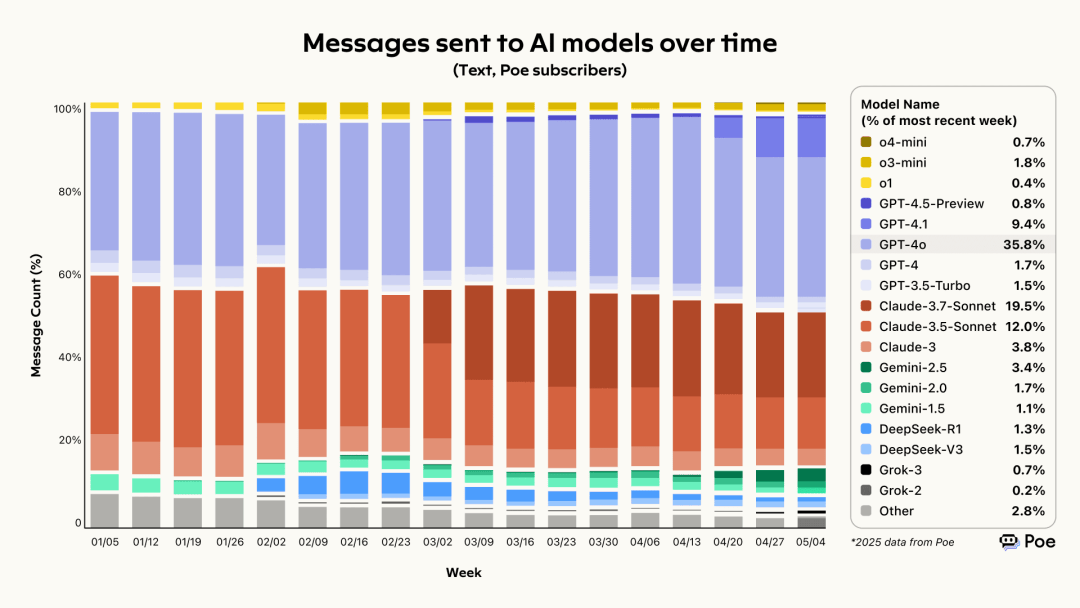
OpenAI很快发布了o3系列模型,作为o1的升级版本,显著提升了数学、科学和复杂推理任务中的表现。o3引入了“私有思维链”机制,使模型在生成回答前进行更深入的思考,尽管响应时间有所增加,但准确性和深度得到了增强。紧接着,GPT-4.5 “Orion”、深度研究功能面世,在推出o3正式版的同时,又推出了o4-mini,进一步向着低幻觉、高情商方向进发,最近亦有GPT-5的消息传出,旨在将多个产品整合为统一系统。
OpenAI和Gemini通过与Azure、Google等平台的深度整合,提供了更无缝的开发者体验,国内的Qwen与阿里生态的绑定,豆包与字节跳动的绑定,在数据猿发布的文章《别再瞎搜了!这个“高搜商”AI“先思考后搜索”秒解生活难题 》中,我们分析了夸克产品搭载了阿里的大模型成为阿里AI的重要入口,根据Data.ai的最新数据,夸克的iphone下载量在中国排名第六。DeepSeek已经掌握“微调”,
新版R1在原有基础上,对议论文、小说、散文等文本类型进行了深化优化,具备生成更长篇幅、更具结构性和内容完整性的能力,同时展现出更符合人类审美与表达习惯的写作风格。另外值得注意的是,DeepSeek R1 0528版本在Live CodeBench权威大模型测评和Artificial Analysis 报告中,分别排名第四和第二。从开源大模型来看,DeepSeek在1月凭借第一个R1版本成为首个跻身榜单排名第二的开源权重模型;而今天发布的R1更新,再次将其推回这一位置。